Visualizing Sound with Spectrograms
This Data Preprocessing Notebook walks through a complete end-to-end pipeline for converting raw audio recordings into normalized Mel-spectrograms ready for 2D CNN training. It begins by loading metadata and setting sampling/Mel-spectrogram parameters, then constructs full file paths and precomputes a Mel filterbank. For each clip it handles NaNs, applies STFT to compute power spectrograms, maps them through the Mel filterbank, converts to decibels and min-max normalizes to [0, 1]. The workflow is accelerated with Joblib for parallel processing, offers debug vs. full-mode execution, saves/loads the aggregated spectrogram array in NPY format, and finally visualizes sample Mel-spectrograms with their class labels

Fine-Tuning with EfficientNet-B0 to Identify the Calls
This Training Notebook implements a full training pipeline using an EfficientNet-B0 backbone (via PyTorch and the Timm library) as a baseline for the challenge. It supports both pre-computed and on-the-fly mel-spectrogram feature extraction, offers a debug mode for quick iteration (2-epoch runs) versus full training (10 epochs), and is built around stratified 5-fold cross-validation with ensembling capability. To improve generalization it includes Mixup augmentation, spectrogram augmentations (time/frequency masking, brightness adjustment), and employs an AdamW optimizer with cosine annealing learning-rate scheduling. You can optionally load pre-computed spectrograms by setting LOAD_DATA = True for faster training iterations .
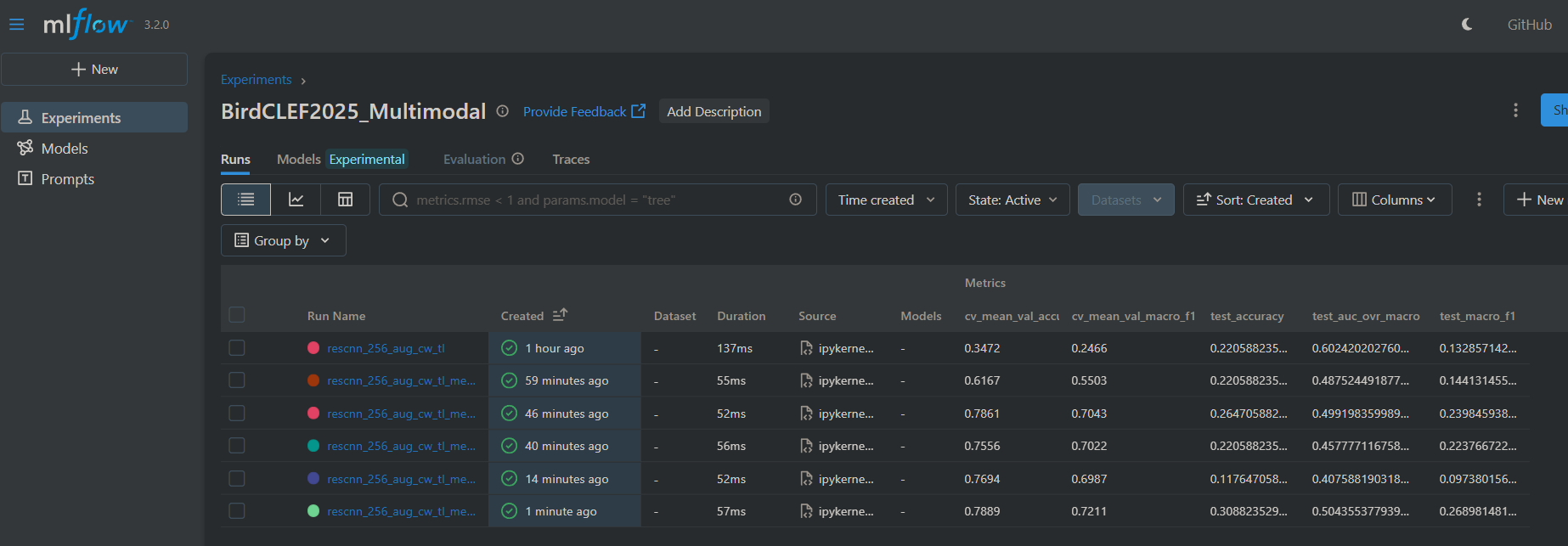
ResCNN Training & Tuning with Augmentation, Transfer Learning, Keras Tuner, and MLflow
This notebook runs end-to-end experiments for a spectrogram classifier built on a Residual CNN. It applies on-GPU augmentation, supports optional transfer learning, performs cross-validation, and uses Keras Tuner to search hyperparameters—while logging parameters, metrics (e.g., macro-F1/accuracy), and artifacts to MLflow for easy comparison across trials. Outputs include best-model checkpoints and training diagnostics to help pick a robust configuration.