
01 — Embedding the Movie Corpus: EDA → Clean Vectors
Generates sentence-level embeddings from movie plot synopses after quick sanity checks in EDA. Normalizes vectors for cosine geometry, saves a reusable .npy artifact, and sets a consistent foundation for downstream similarity search and graph analytics.
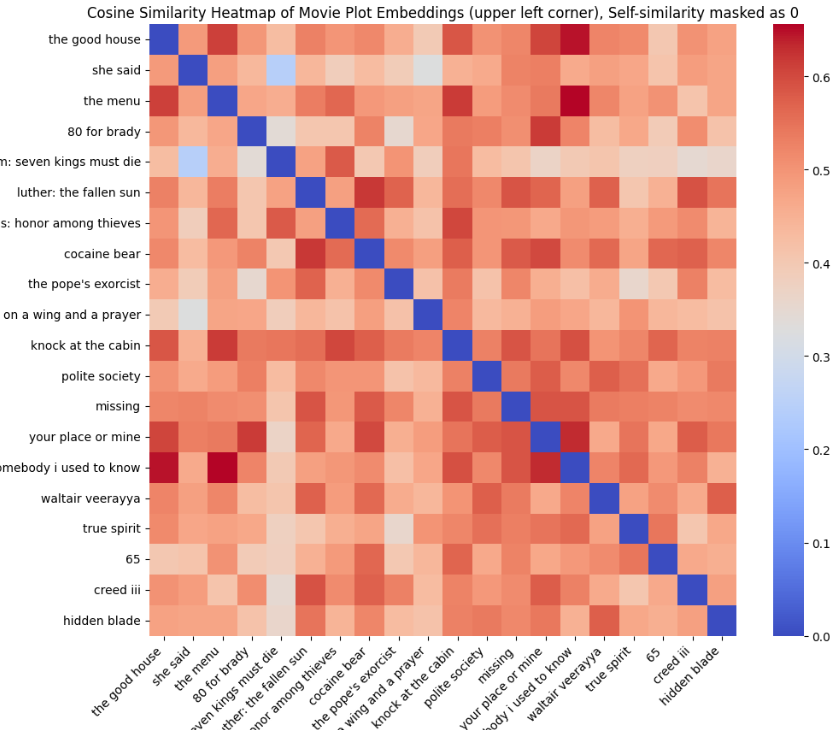
02 — Pairwise Cosine Similarity: Validating Semantic Neighborhoods
Builds and inspects a cosine-similarity matrix over the embeddings to surface near-duplicates, sequels, and tight thematic clusters. Highlights top-k neighbors per title and uses thresholds/heatmaps to confirm that the representation captures meaningful plot-level semantics.

03 — Redis Vector Search: Low-Latency ‘More Like This’
Creates a RediSearch index with text/numeric metadata and a vector field, ingests the corpus, and implements KNN queries using the same embedding model. Demonstrates responsive semantic search with optional hybrid filters (e.g., year/genre) and lays the groundwork for a simple API.

04 — Neo4j Graph Analytics: Communities & Influence
Materializes a similarity graph in Neo4j (nodes = movies, edges = weighted similarity) and runs GDS algorithms like PageRank, Betweenness, and Louvain. The results reveal influential bridge titles and community structure, useful for recommendations, playlists, and catalog exploration.